В ходе анализа данных бывает необходимость собрать в одном отчете данные из различных систем-источников. Забрать эти данные для анализа бывает не всегда просто, у части систем есть стандартизированное публичное API, а для другой части приходится придумывать новые способы.
AlphaBI позволяет извлекать данные из разных типов источников: из файлов, баз данных, web-сервисов. Это позволяет закрыть 99% сценариев извлечения данных.
С помощью ETL-процесса можно выгрузить данные из нескольких источников одновременно, обработать их и загрузить. Загрузить как во внутреннее аналитическое хранилище, так и во внешний источник, будь то файл, таблица внешней базы данных или публикация в веб сервис. То есть откуда данные можно забрать, туда же их можно и загрузить. Это позволяет модулю ETL-процессов решать задачи как самостоятельно, так и успешно работать в комплексе с другими модулями AlphaBI.
Поддерживаемые источники данных
Инструмент ETL может взять данные из следующих источников (все источники можно использовать параллельно и одновременно):
- РСУБД
- Oracle
- ClickHouse
- MS SQL Server
- PostgreSQL
- MonetDB
- MySql
- InfiniDB
- Vertica
- Greenplum
- Файлы
- Расположение
– Внутреннее файловое хранилище
– сетевой диск
– FTP сервер - Типы файлов
– xml
– json
– xls/xlsx
– dbf
– csv
- Веб сервисы
- RESTful API
- SOAP
- Системы
- Запрос к базе 1С
- Запрос к данным собственных объектов
Кейсы
Задача 1: мы хотим аккумулировать информацию из разных источников в одном месте, например, извлечь данные из таблицы в БД и добавить их к данным из CSV-файла. При этом нам нужно знать, к какому именно источнику относится каждая строка данных.
Задача 2: нужно объединить данные, поступившие от филиалов в разных файлах/на разных листах XLSX-файла, и построить на них единый отчет или OLAP-представление для понимания общей ситуации по компании и по отдельности в каждом филиале. При этом одна часть пользователей должна иметь доступ ко всем данным отчета, а другая – только к данным своего филиала.
Решение: в Системе нужно создать один ETL-процесс и один бизнес-объект. В бизнес-объект добавить столбец, который будет хранить название источника. На этапе обработки для каждого источника добавить столбец с его названием, далее объединить данные и загрузить их в бизнес-объект. В зависимости от потребностей пользователей, создать плоскую или многомерную модель данных и использовать их при построении отчета или аналитической панели (а как это настроить - опишем в отдельной статье).
Как настроить
Задача 1
Рассмотрим задачу 1 - объединение данных из разных типов источников данных.
Чтобы обработка данных не отвлекала от основной темы статьи, в нашем случае будут использоваться наборы данных с одинаковой структурой.
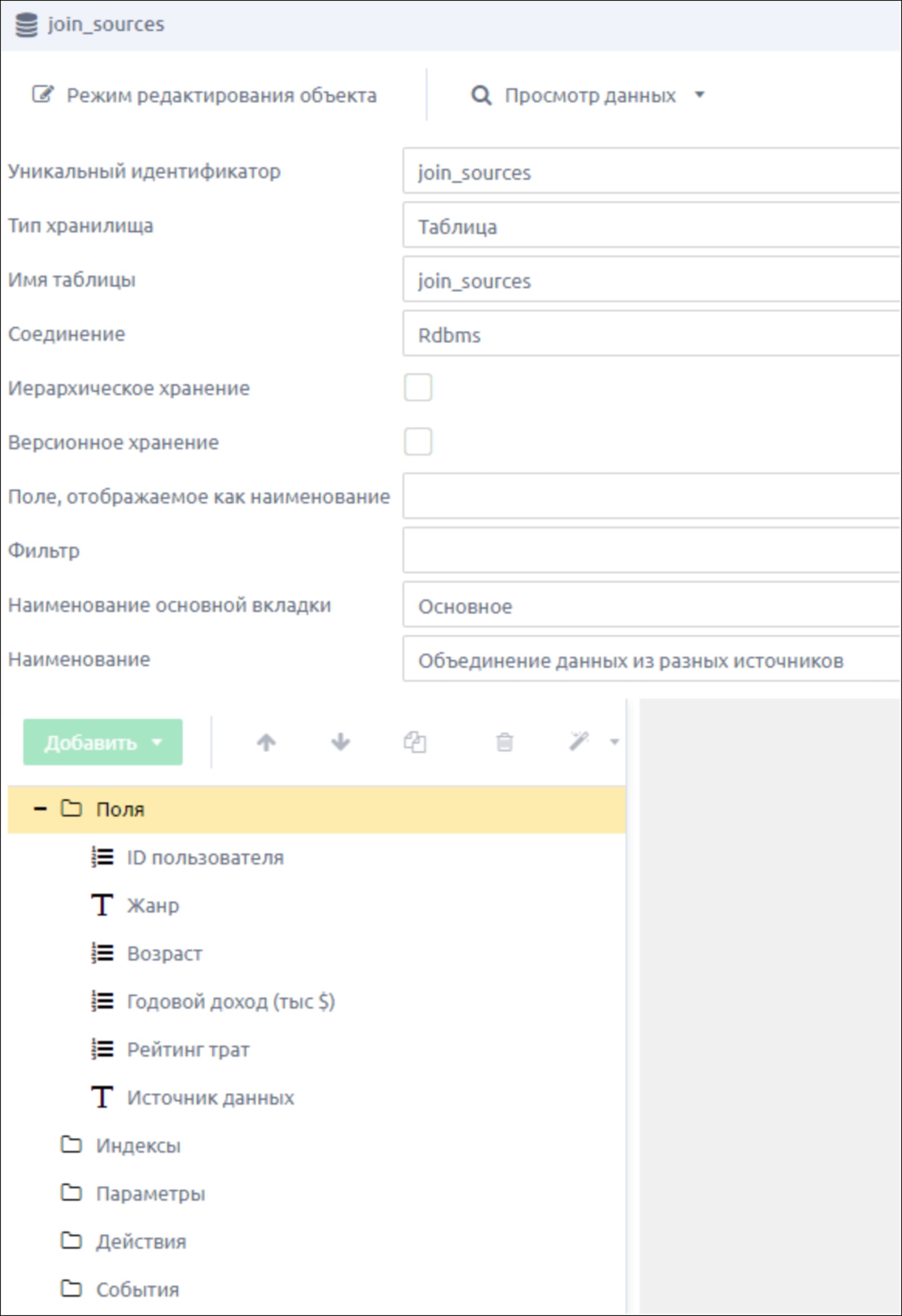
1. Бизнес-объект
В разделе Система создаем бизнес-объект с типом «Таблица» для хранения аккумулированных данных. Добавляем 6 полей: пять, в которые будут грузиться данные из источников, и один – в котором будет храниться название источника. После сохранения публикуем БО, синхронизируем схему.
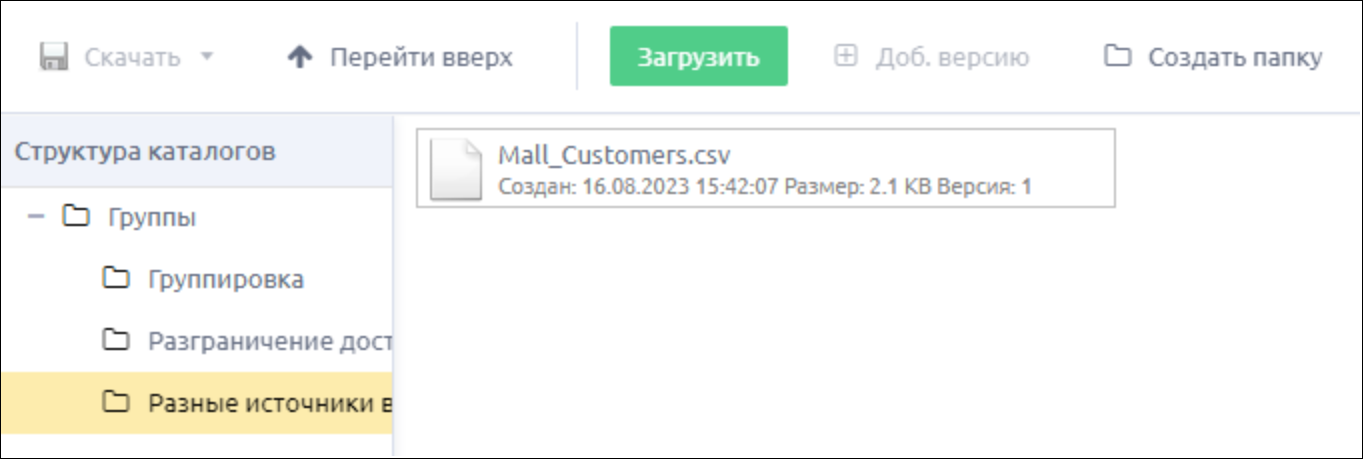
2. Загружаем CSV-файл в файловое хранилище
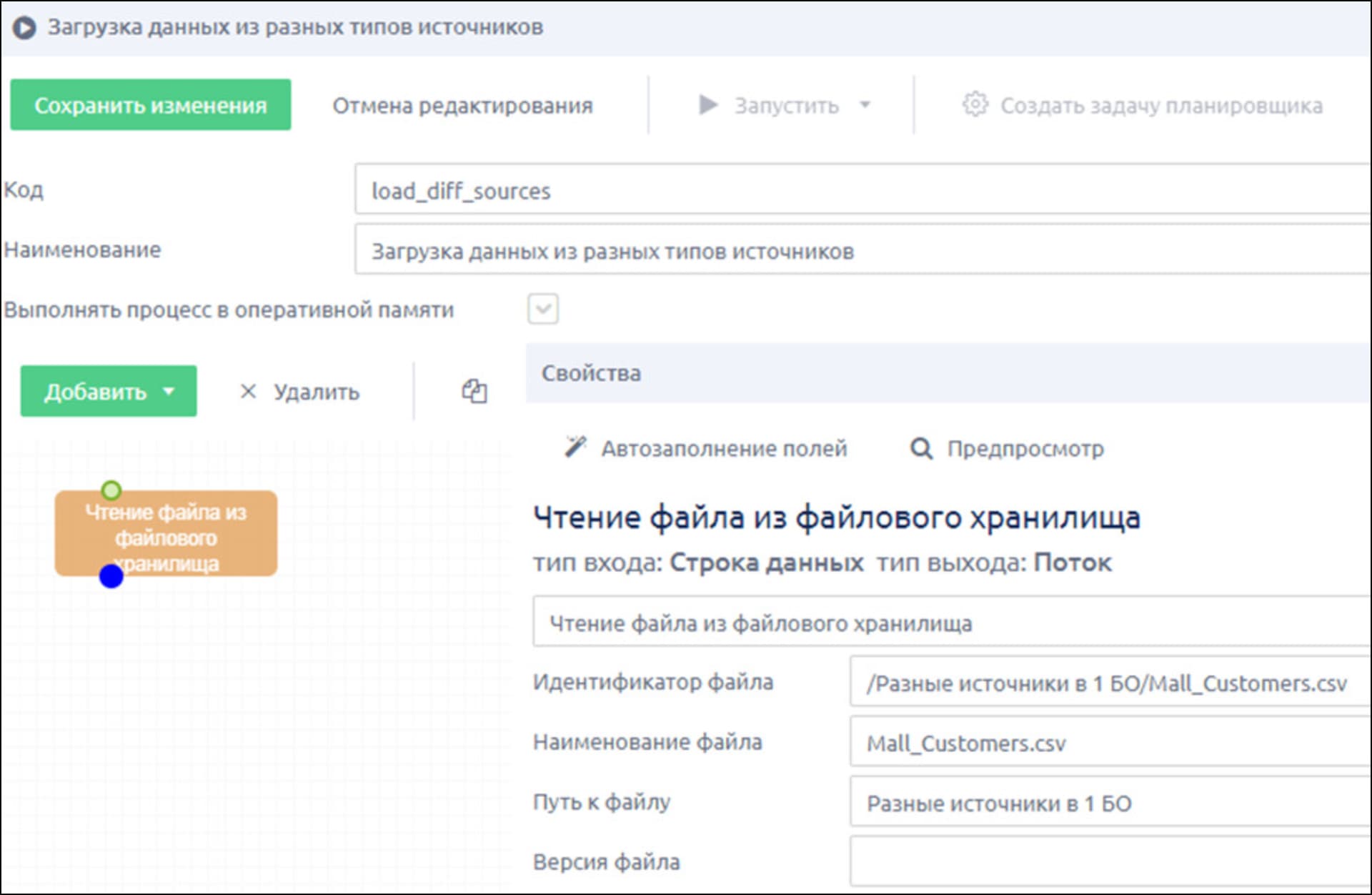
3. ETL-процесс
Для создания ETL-процесса нужно добавить шаги:
3.1 Чтение файла из файлового хранилища (первый источник данных)
- добавляем шаг Входные данные → «Чтение файла из файлового хранилища»
- выбираем ранее загруженный файл
- нажимаем кнопку «Автозаполнение»
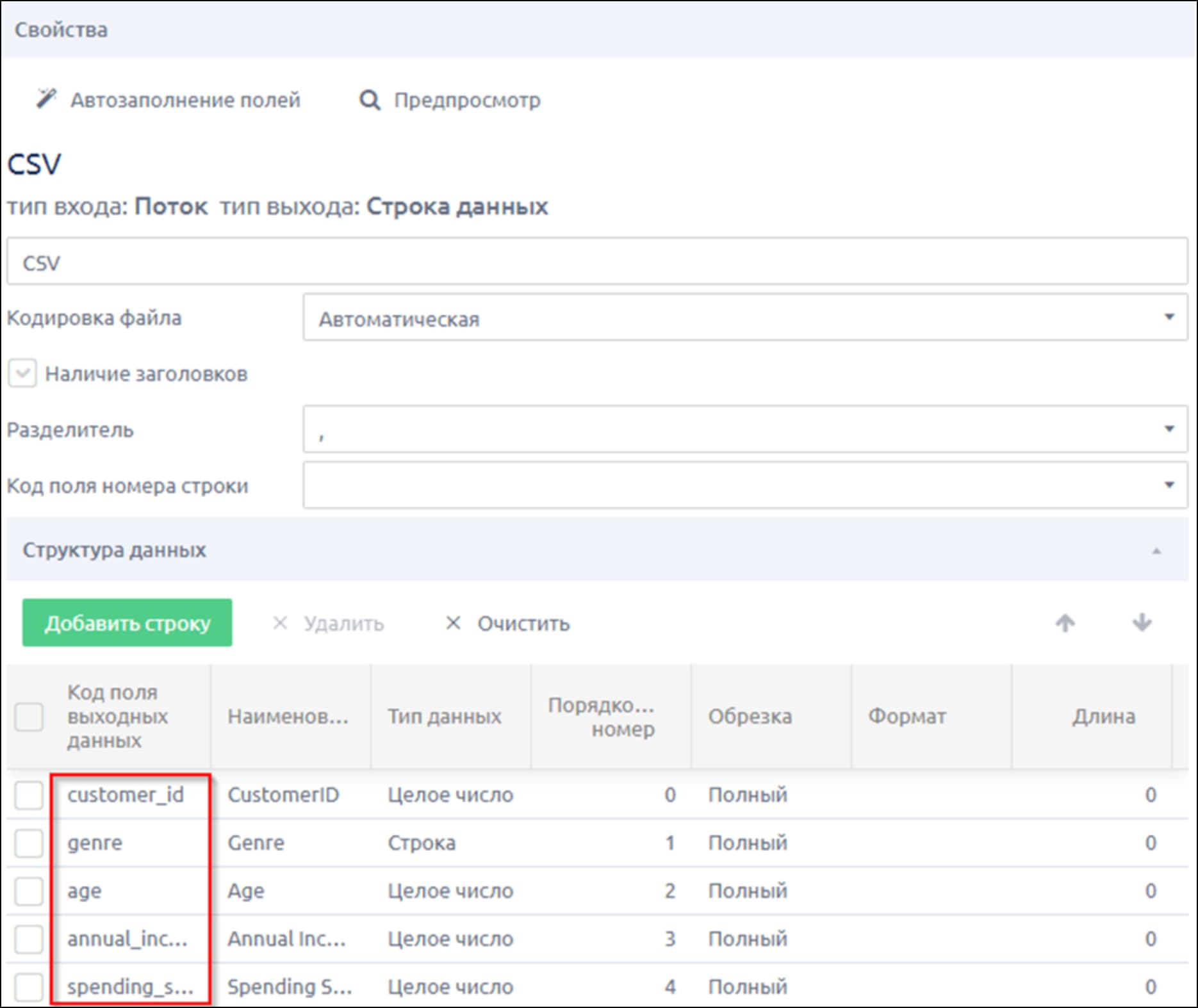
3.2 Извлечение данных из CSV-файла
- добавляем шаг Извлечение → «CSV»
- протягиваем связь от предыдущего шага
- задаем разделитель (в нашем случае – запятая)
- меняем тип данных в полях
- ставим флажок «Наличие заголовков»
- нажимаем кнопки «Автозаполнение» и «Предпросмотр»
В окне просмотра проверяем, что данные отображаются корректно. На этом этапе важно задать коды полей выходных данных как в бизнес-объекте или в других источниках данных - это нужно, чтобы данные из разных источников объединились в один столбец на этапе накопителя или записи в БО
3.3 Добавление столбца с названием источника данных
- добавляем шаг Обработка → «Калькулятор»
- протягиваем связь от предыдущего шага
- нажимаем кнопки «Заполнить поля» и «Добавить строку»
- вводим код и наименование столбца, в котором будет храниться название источника данных
- выбираем тип данных – Строка и в поле «Формула» задаем текст, который хотим видеть в этом столбце
Так как нам важно видеть именно название источника данных, вводим значение «file» (что данные получены из файла). Текст можно ввести сразу в поле или воспользоваться blockly в редакторе формул.
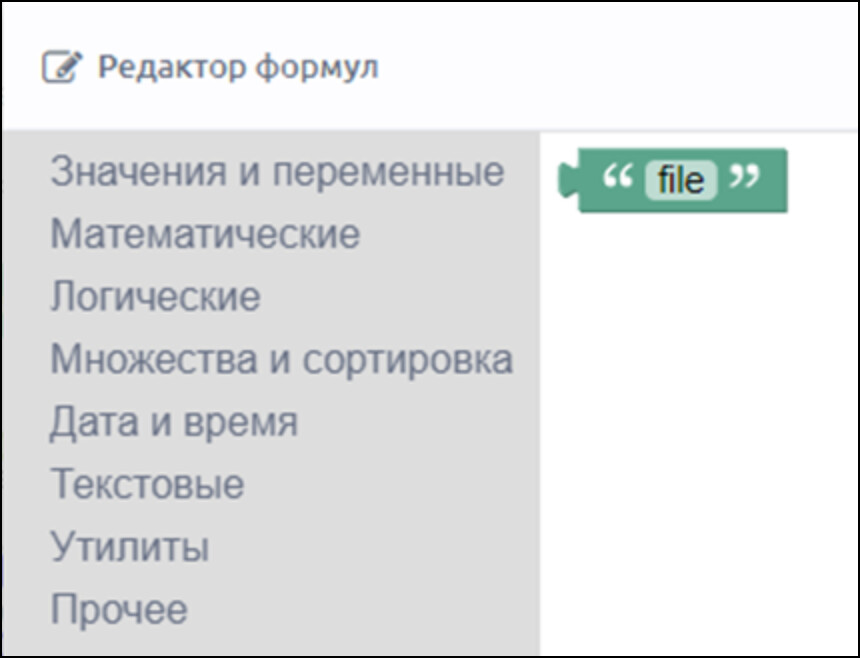

3.4 Запрос к базе данных (второй источник данных)
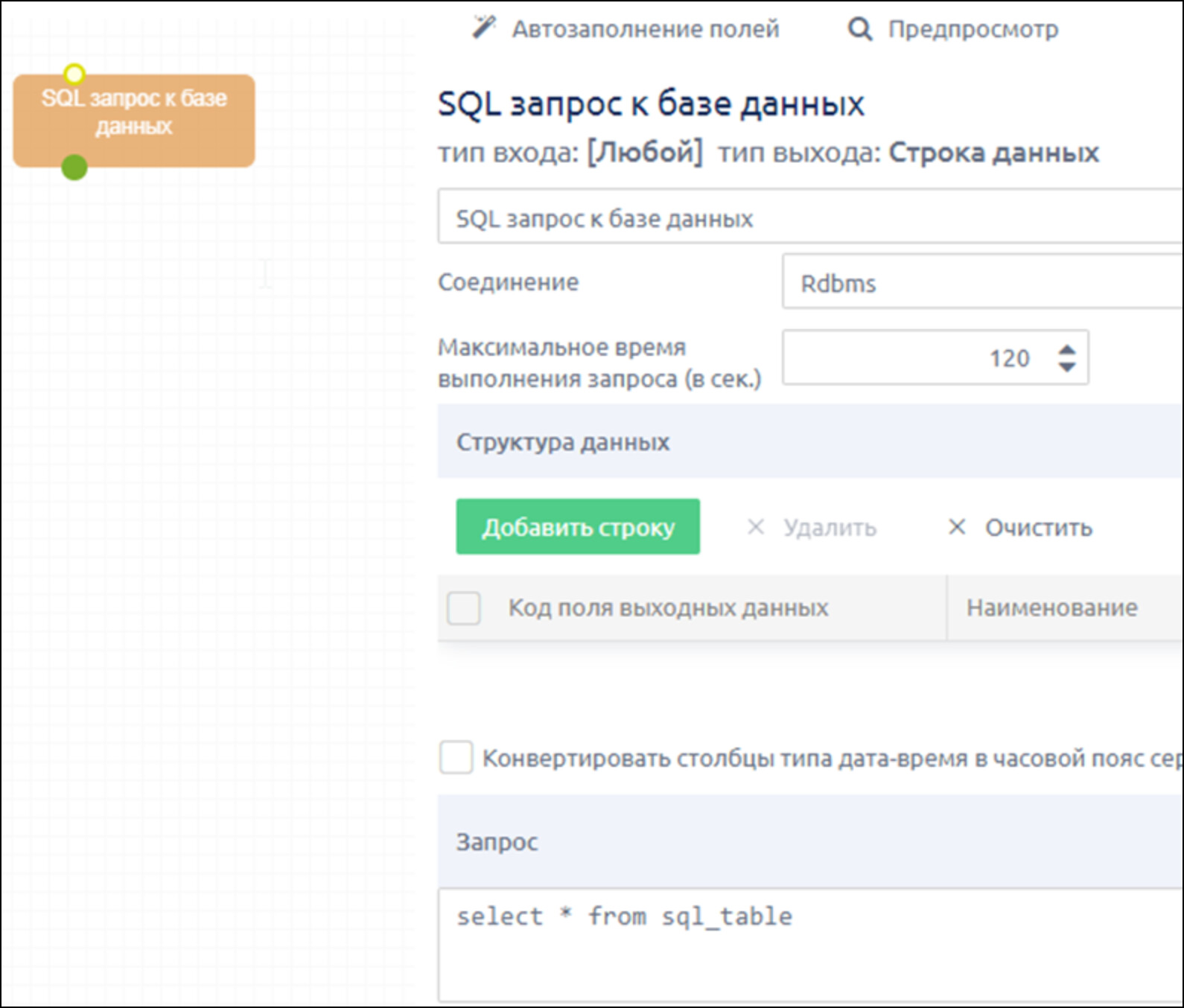
- добавляем шаг Входные данные → «SQL запрос к базе данных»
- выбираем соединение
- в поле «Запрос» вводим текст SQL-запроса (в нашем случае забираем все столбцы из таблицы)
- нажимаем кнопку «Автозаполнение полей» и «Предпросмотр»
Убеждаемся, что запрос отработал и данные получены. Также проверяем, что коды полей выходных данных совпадают с кодами в предыдущем источнике
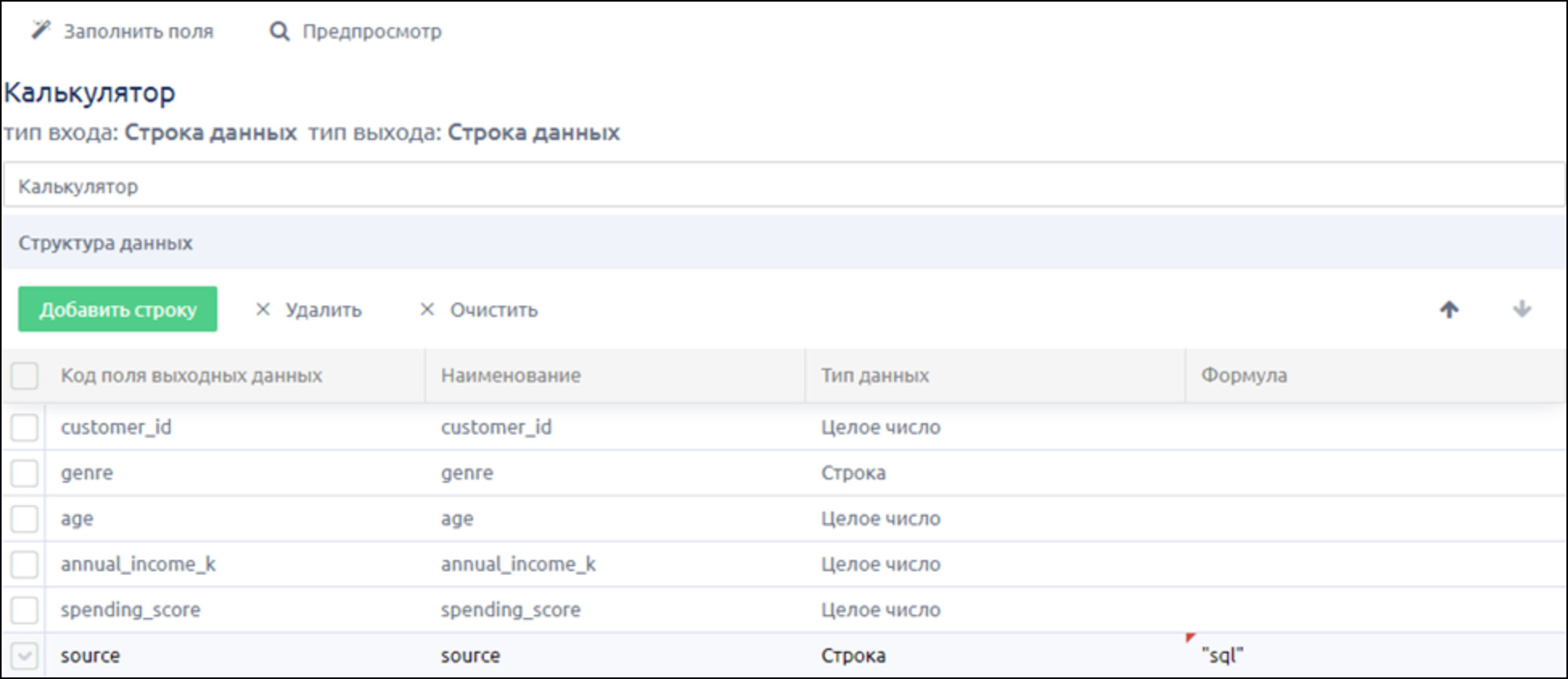
3.5 Добавление столбца с названием источника данных
- добавляем шаг Обработка → «Калькулятор» по аналогии с п.3, но в поле «Формула» пишем «sql»
- протягиваем связь от предыдущего шага
Таким образом можно добавить неограниченное количество источников данных, в нашем примере ограничимся двумя. На вкладке «Дерево» можно посмотреть, в какой последовательности будут выполняться шаги ETL-процесса.
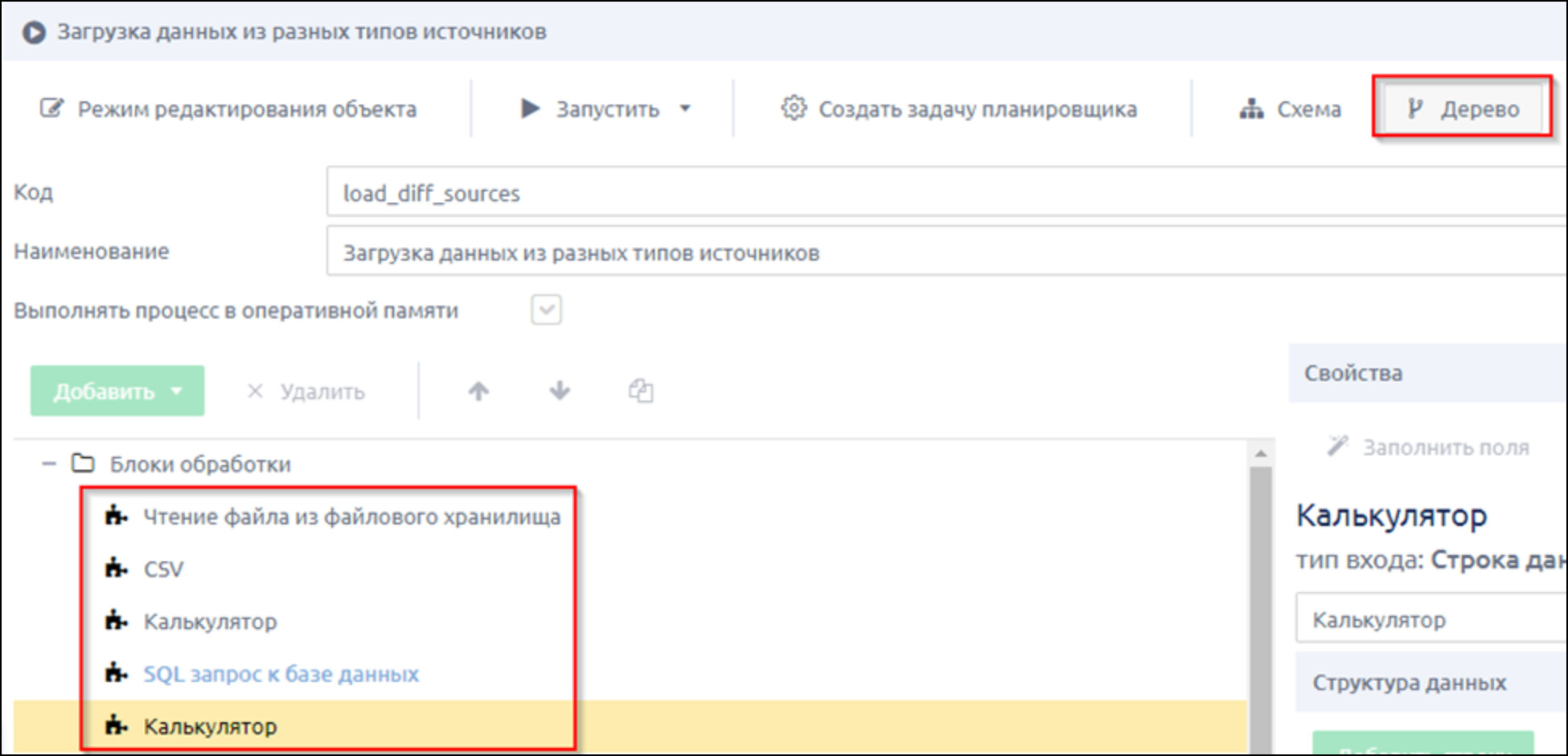
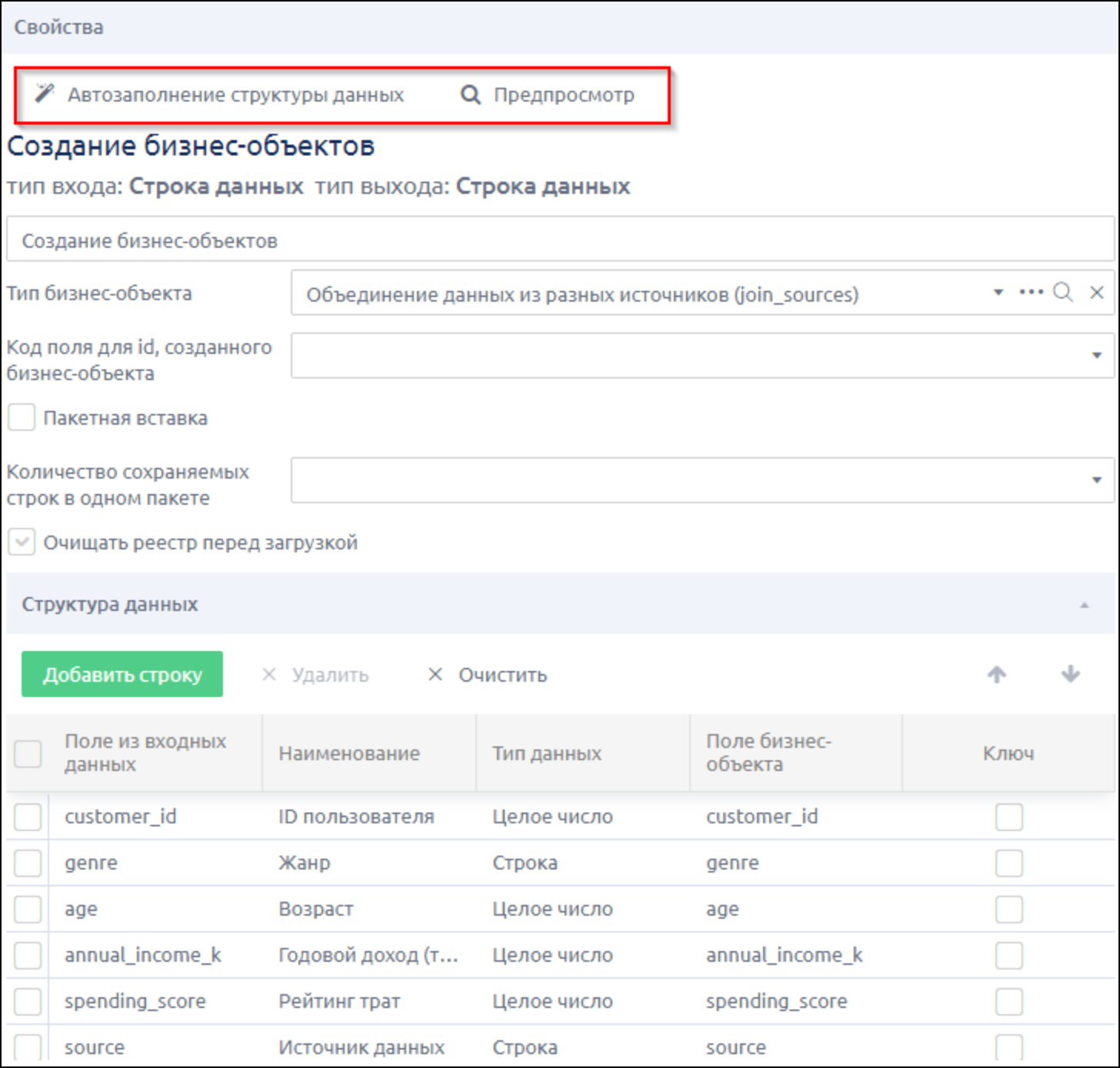
3.6 Запись данных в бизнес-объект
- добавляем шаг Запись → «Создание бизнес-объектов»
- выбираем ранее созданный бизнес-объект
- ставим флажок «Очищать реестр перед загрузкой» (если планируется полностью перезаписывать данные)
- нажимаем кнопку «Автозаполнение структуры данных» и «Предпросмотр»
Убеждаемся, что данные в столбцы записались верно, источник данных для каждой строки указан.
В результате настроенная схема ETL-процесса будет выглядеть так:
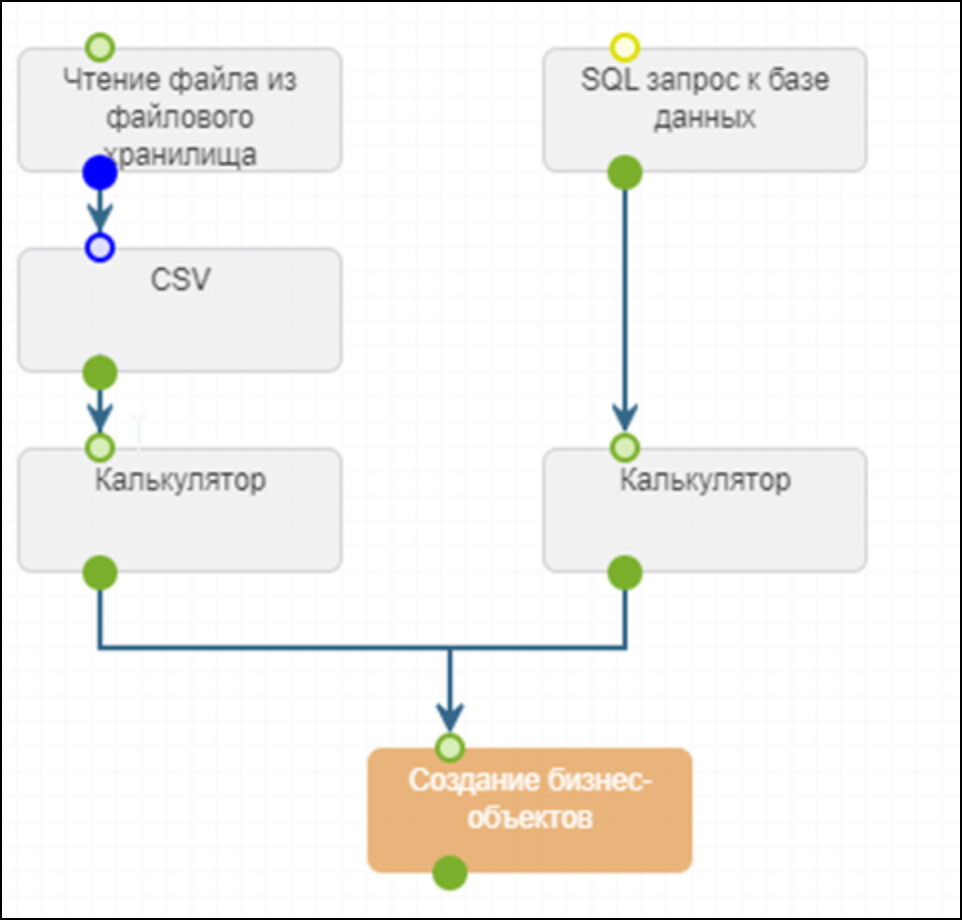
Для удобства хранения и просмотра данных в бизнес-объекте можно добавить дополнительные шаги обработки данных, например, фильтрации, сортировки или группировки данных (более подробно о группировке мы рассказываем в статье https://community-bi.bars.group/t/sposoby-gruppirovki-dannyh/238). В таком случае, после шага «Калькулятор» нужно добавить шаг «Накопитель», который объединит строки, полученные из каждого источника, в набор строк, с которым можно проводить дополнительные операции.
Опционально:
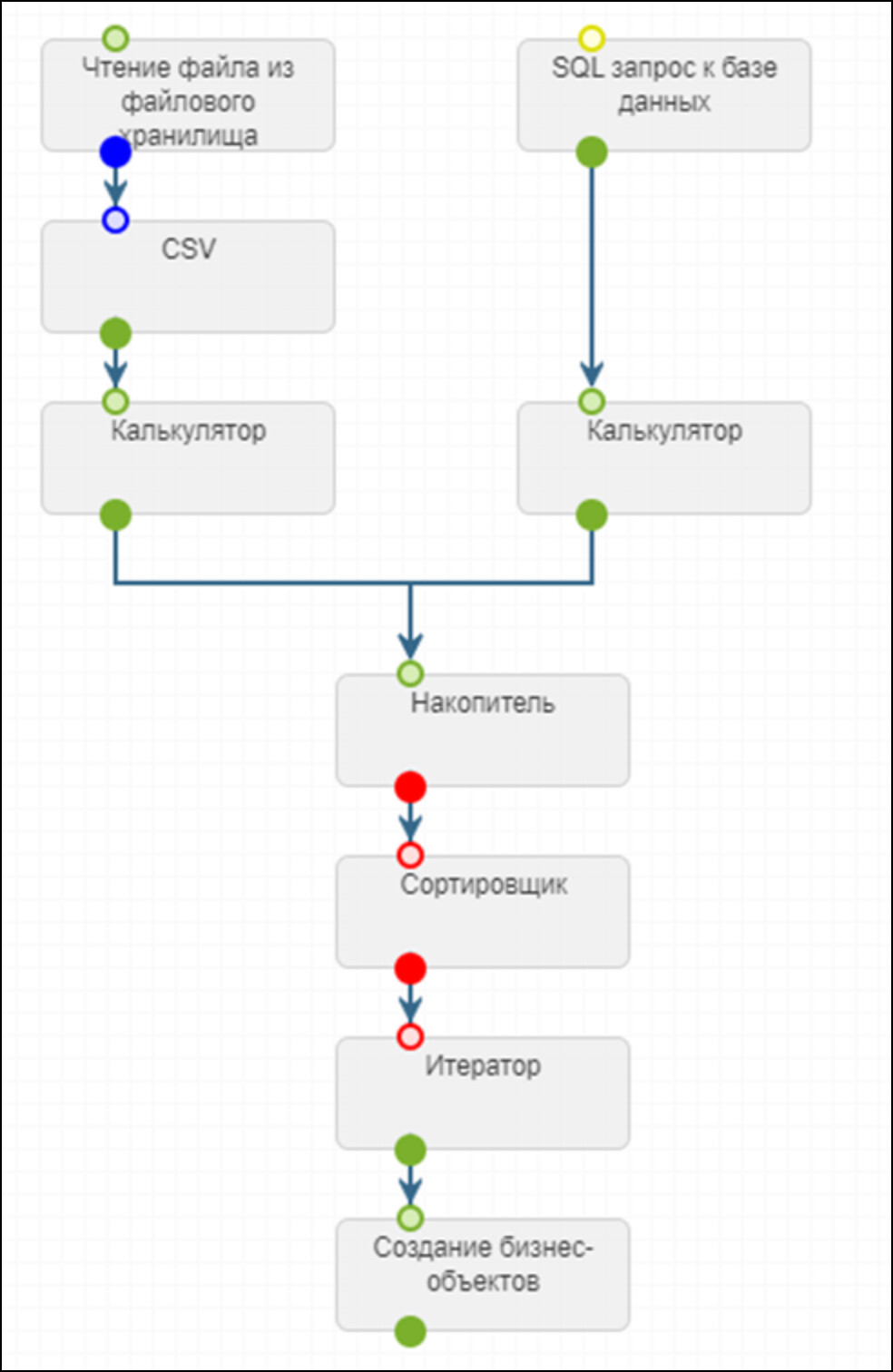
- Добавляем шаг Обработка → «Накопитель», протягиваем связи от всех источников, нажимаем кнопку «Предпросмотр» - убеждаемся, что данные объединились (при необходимости можно увеличить количество строк в предпросмотре и воспользоваться фильтрами/сортировкой.
- Добавляем шаг Обработка → «Сортировщик», протягиваем связь о предыдущего шага, нажимаем кнопку «Автозаполнение полей», в разделе «Сортирующиеся поля» добавляем поле сортировки и выбираем тип сортировки
- Добавляем шаг Обработка → «Итератор», который нужен для преобразования набора строк в обратно в отдельные строки.
Далее можно записывать данные в бизнес-объект. С дополнительными шагами обработки схема ETL-процесса будет выглядеть так:
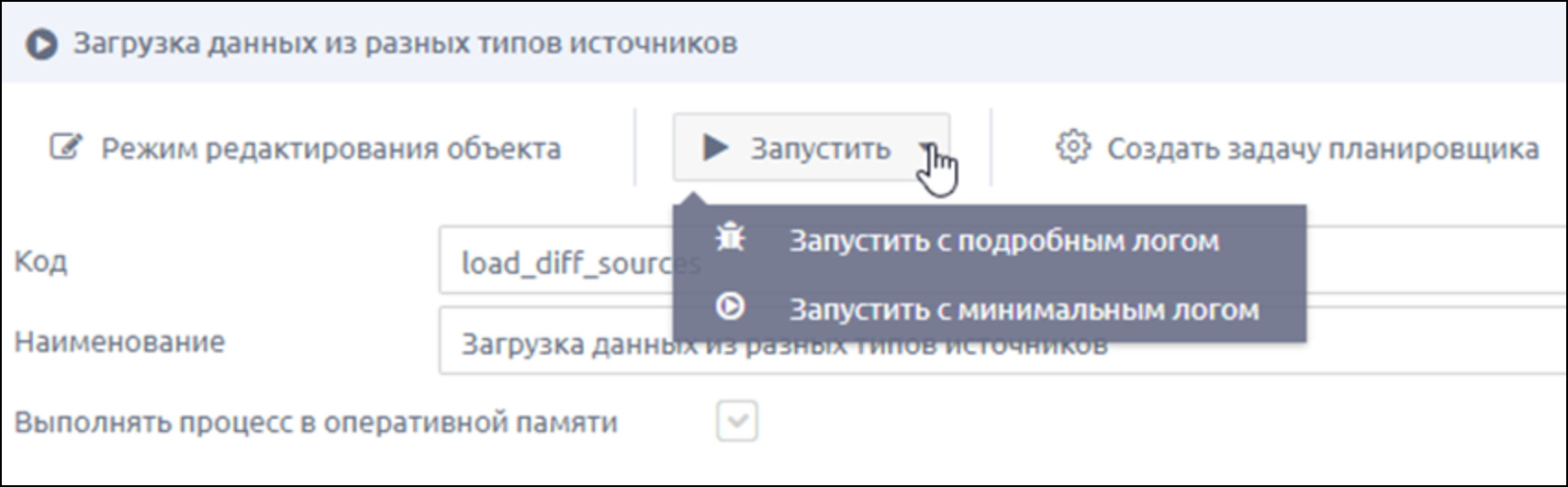
3.7 Сохраняем и запускаем ETL-процесс
4. Просмотр данных БО
После успешного результата выполнения процесса переходим в бизнес-объект и нажимаем кнопку «Просмотр данных» (на момент публикации статьи доступно два варианта просмотрщика). Дополнительно можно получить количество строк.
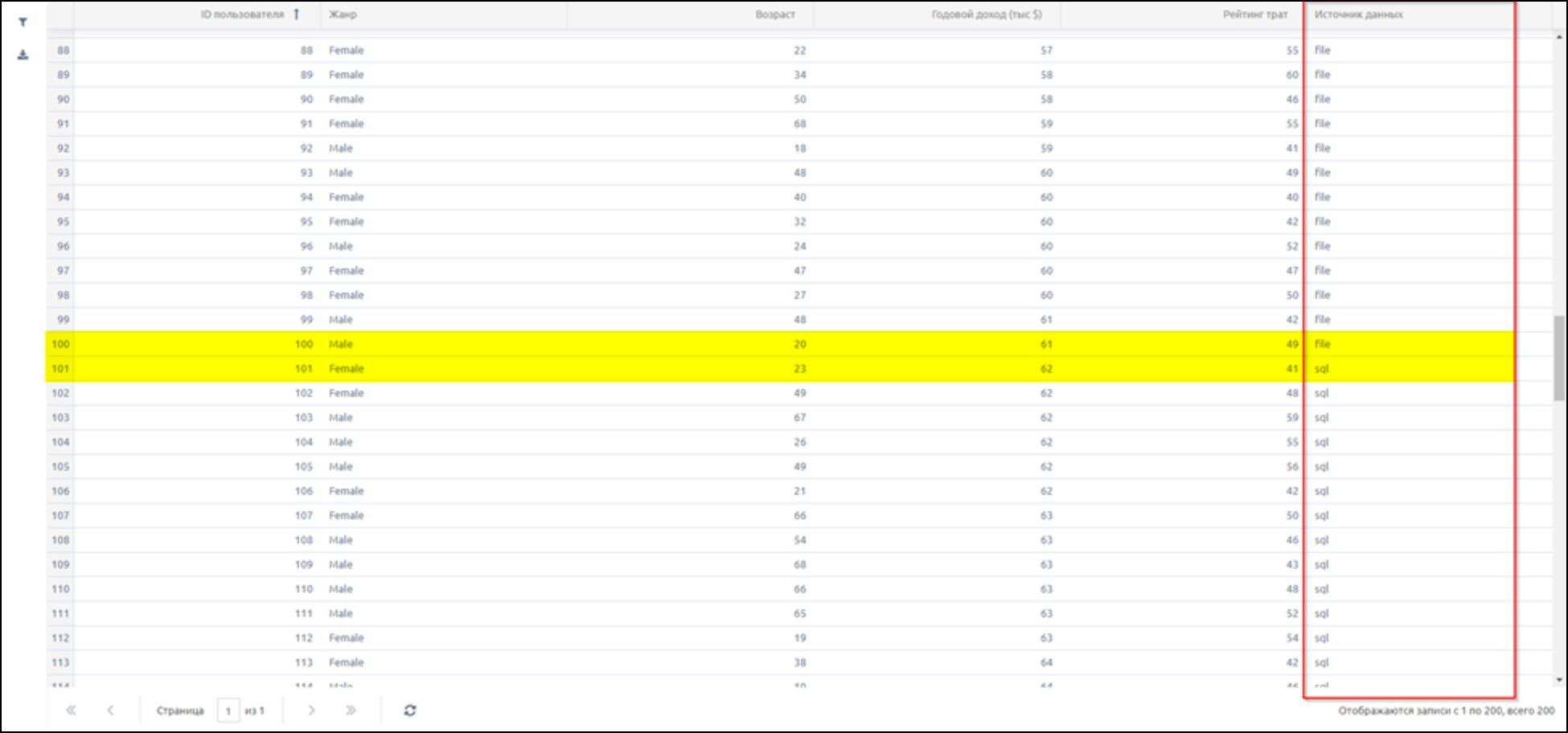
В содержимом бизнес-объекта видим, что для каждой строки указано название источника, из которого она получена:
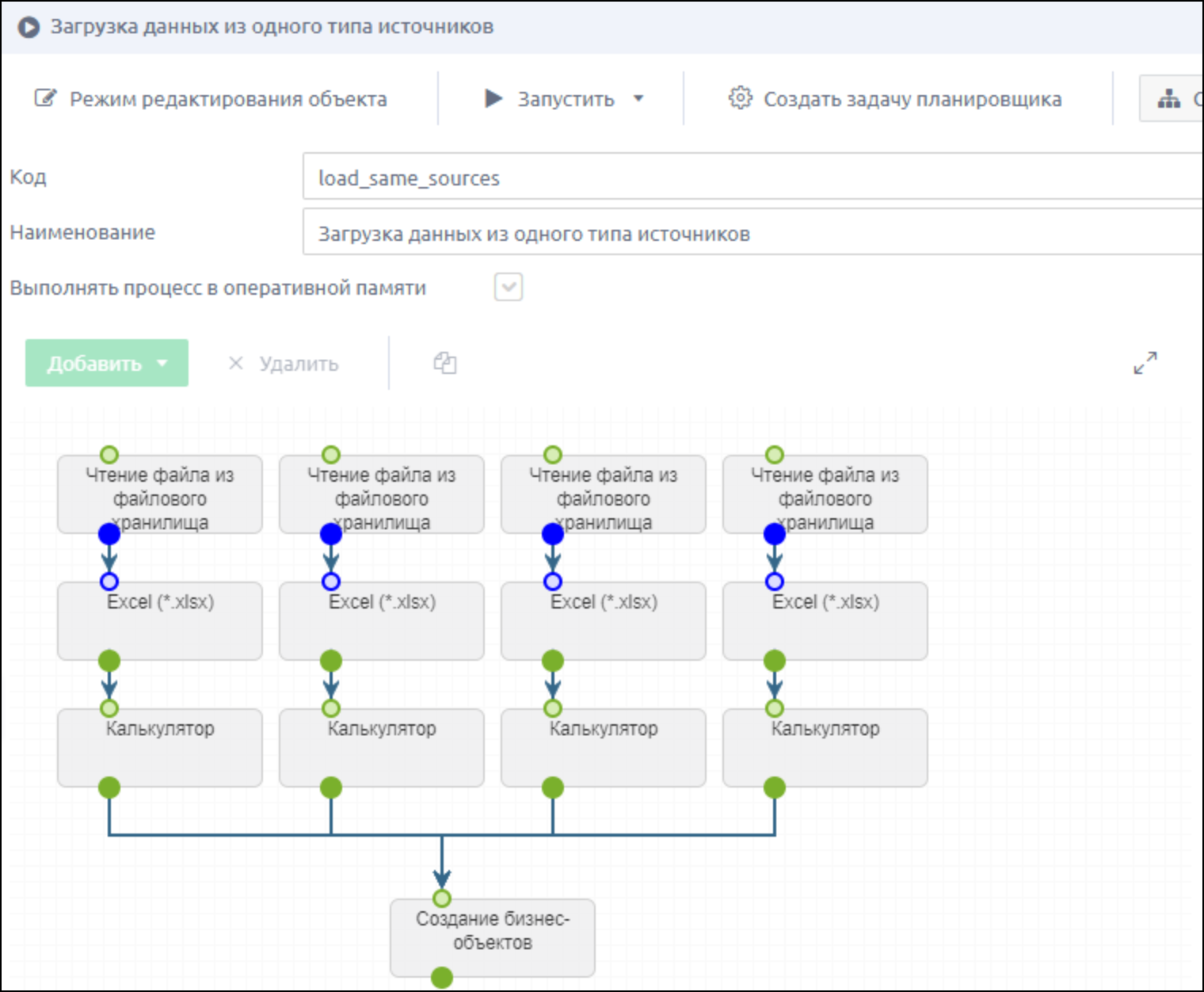
Задача 2
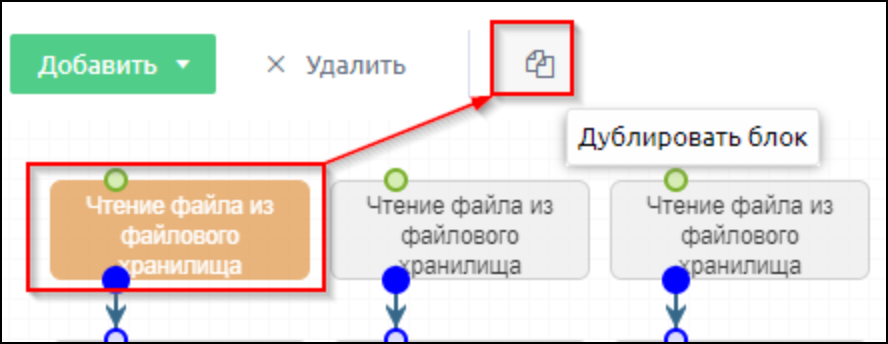
Для задачи 2 - объединение данных из одного типа источника - процесс настройки будет схожим, а упростить процесс добавления однотипных шагов можно функцией копирования (для этого нужно выбрать шаг, нажать кнопку “Дублировать блок”, после чего протянуть новые связи и изменить значения в настройках блока).
В ходе решения этой задачи мы:
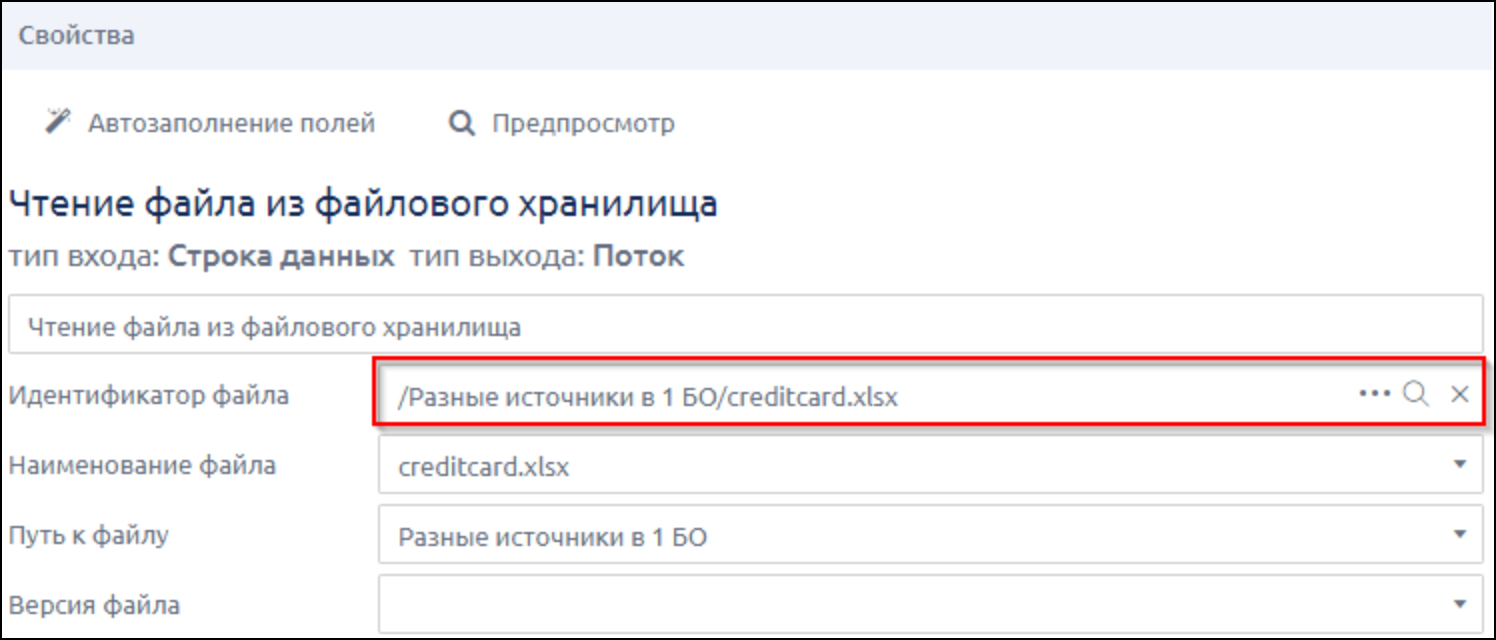
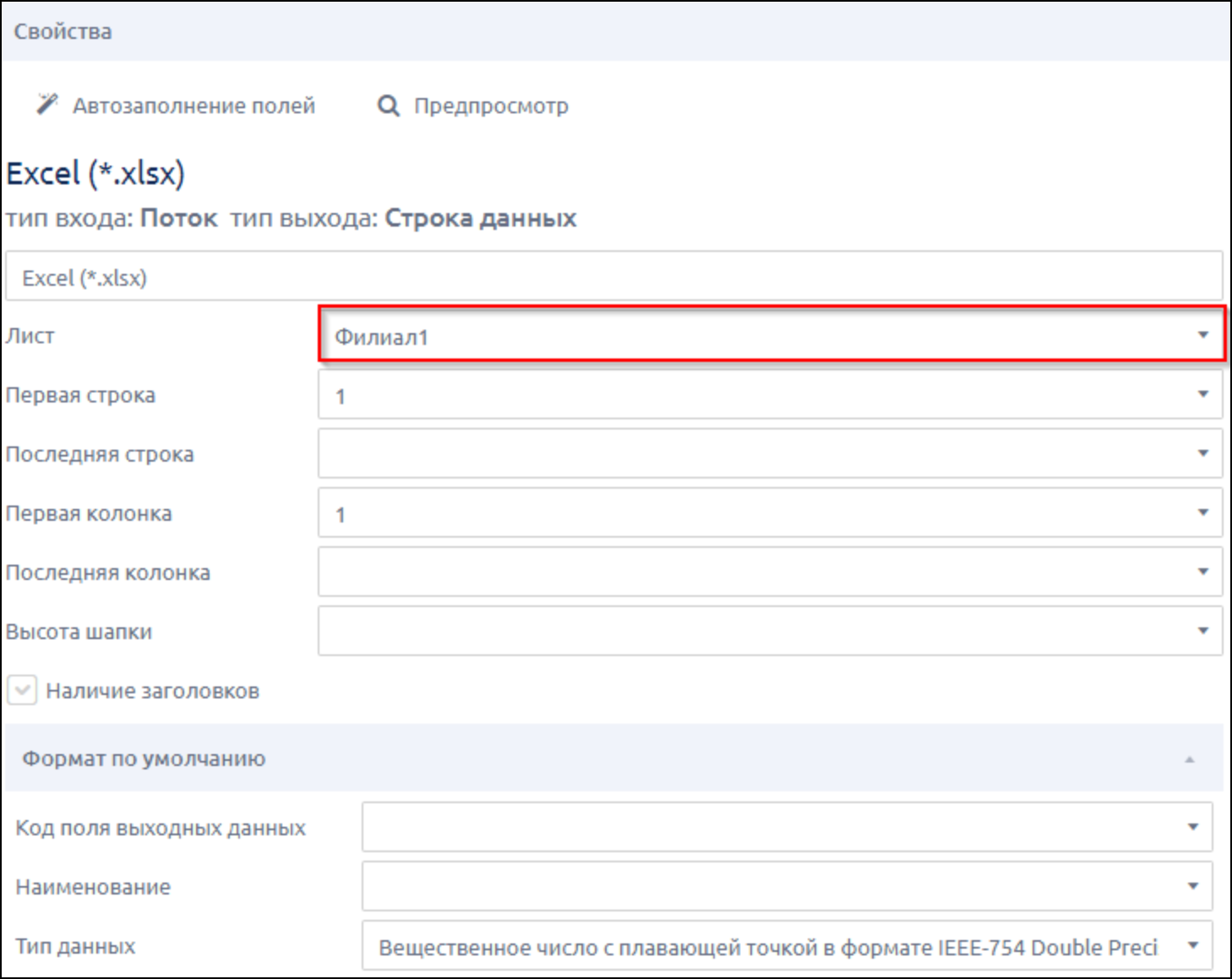
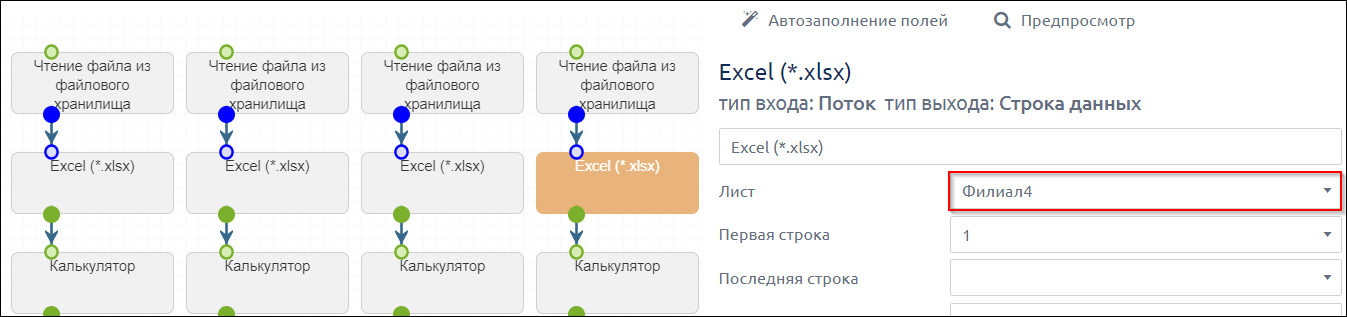
- обратились к файлу
- указали название листа
- добавили название источника
- скопировали эти шаги, протянули между ними связи и изменили название листа и название источника
- добавили шаг “Создание бизнес-объектов” и протянули к нему связи от всех источников.
ETL-процесс для решения этой задачи будет выглядеть так:

Основные преимущества и недостатки
Вариантов решения этих задач может быть несколько. Основное преимущество данного способа - в простоте реализации. Недостатками можно считать необходимость задания одинаковых кодов полей и множественного копирования шагов ETL-процесса при большом количестве источников данных.
Мы будем рады, если вы поделитесь своим способом решения этих задач в комментариях - это будет полезно всем участникам сообщества ![]()